Quick Start
This tutorial will guide you through creating a table, adding data, and sending a query from the command line.
1.
First, Log In or Sign Up. You'll need to be logged in to get your query token.
2.
Let's create a table and insert some data. Run the following query from the Console Page. This page executes SQL queries and shows you the results.
create table [username].mynotes (
id int64 not null,
note string(max)
) primary key (id);
insert into [username].mynotes (id, note)
values
(1, "this is my first note"),
(2, "and this is my second!");This query creates a table called [username].mynotes and inserts 2 rows. You can execute both queries at once by pasting into the Console page and clicking Run.
3.
Now let's query the data we inserted. Run the following query:
select * from [username].mynotesYou'll see the content of the rows you inserted in step 2. The console can run any valid SQL query. Of course, you may also want to query this table from your own application.
4.
Get an Identity Token from the Account Page. The token is a UUID that looks something like this: 0564f9af-0ce1-4c69-8749-078a2d1215cf.
The token is how you'll authenticate your query. It allows a request to act as your account and query your tables. It's sensitive like a password, be careful not to show it to others or check it in to version control like Git.
5.
Now that we have the token we can query Commonwealth from anywhere. Run the following from a MacOS or Linux shell. This sends an HTTPS request to Commonwealth and returns results as JSON.
curl -XPOST 'https://api.commonwealth.io/sql' \
-H 'x-auth-token: [your token]' \
-d 'select * from [username].mynotes';That's it! You've just sent an SQL request and gotten results back. This SQL interface allows a full range of queries, and you can query from anywhere.
Commonwealth has been built for ease of use, and this makes it ideal for a serverless app like one built in AWS Lambda.
Quick Start with AWS Lambda
In the previous Quick Start we queried Commonwealth from the command line using your credentials. Now let's query Commonwealth from a Lambda function, demonstrating how to access Commonwealth from your own app.
1.
Log in to AWS and go to the AWS Lambda Console.
2.
Create a new function. You can also use one of your existing functions, in that case just skip this step.
Use the following settings when creating a new function.
| Name | commonwealth-tutorial |
| Runtime | Node.js 6.10 |
| Role | Create a new role from templates |
| Role name | commonwealth-tutorial |
| Policy Templates | Basic Edge Lambda permissions |
Creating a new Lambda function looks like: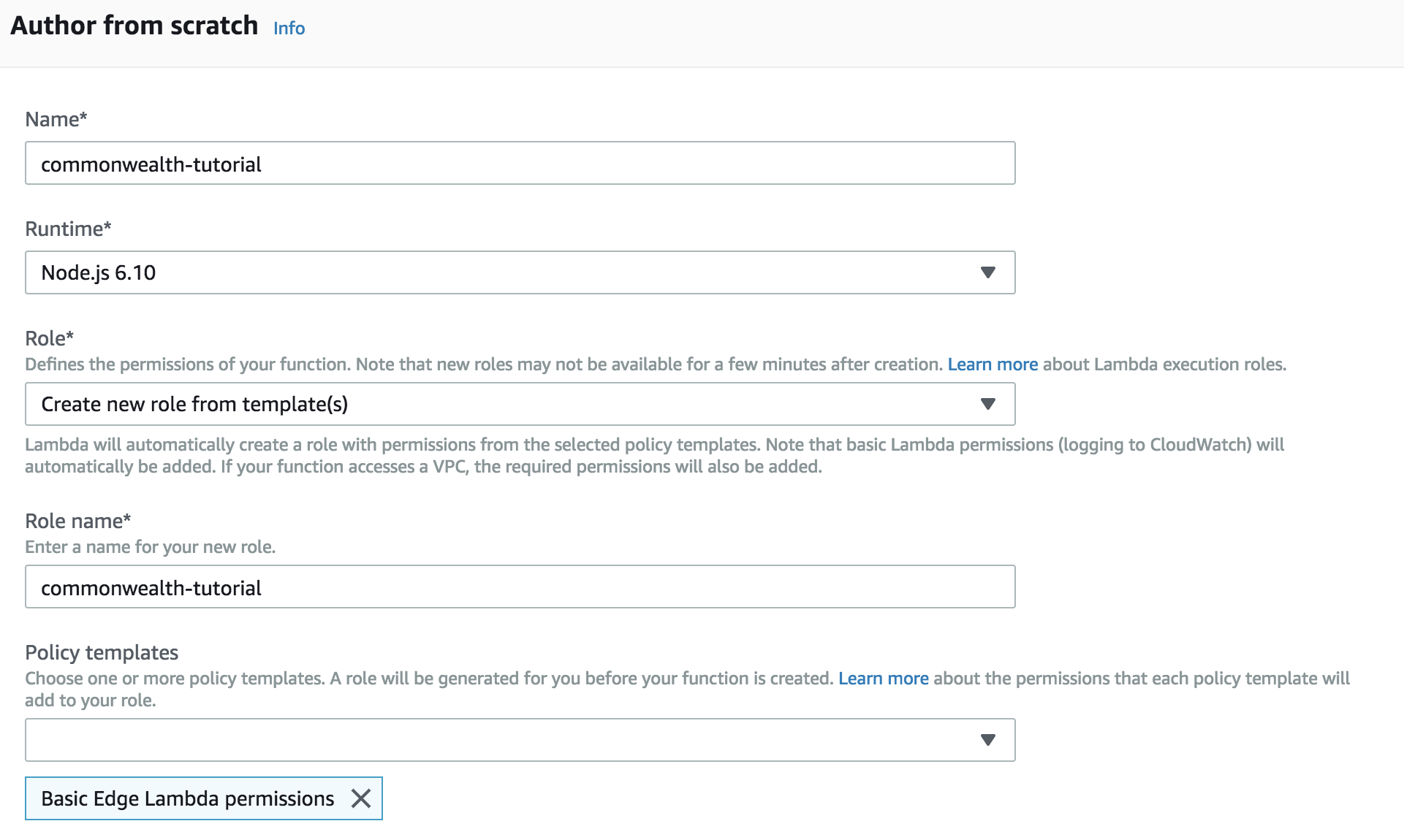
3.
Set env var COMMONWEALTH_TOKEN to your identity token. This passes your credentials through to the function.
Adding your token looks like:
4.
Create a Lambda function that looks like the following.
const https = require("https");
const commonwealthToken = process.env['COMMONWEALTH_TOKEN'];
function queryDatabase(query) {
if (!commonwealthToken) {
console.error('Missing expected env var COMMONWEALTH_TOKEN');
}
var options = {
host: 'api.commonwealth.io',
path: '/sql',
method: 'POST',
headers: { 'x-auth-token': commonwealthToken }
};
var parsedResponse = undefined;
var req = https.request(options, function(res) {
res.setEncoding("utf8");
let body = "";
// collect response data as it comes in
res.on("data", data => {
body += data;
});
// wait for request to end and parse JSON result
res.on("end", () => {
parsedResponse = JSON.parse(body);
});
});
req.on('error', function(e) {
console.error(e);
});
req.write(query); // send query body
req.end(); // wait for query to finish
return parsedResponse;
}
exports.handler = function(event, context, callback) {
var results = queryDatabase("select * from example.foo");
console.log(results);
}
This exports a Lambda handler function that runs a query and prints the results if successful.
5.
Let's execute the function: click the Save button at the top of the page, then click Test. If all goes well this should execute a query from your Lambda function into Commonwealth!
The function you just wrote is sending an HTTPS request to the Commonwealth server, running a SQL query, and processing the request. You can copy this code into other Lambda functions and call queryDatabase() whenever you want to run a query. Commonwealth is designed to be easy to use, accessible from anywhere, and very scalable. If you have any trouble check out the full documentation below or contact us at contact@commonwealth.io. Happy querying!
Querying Commonwealth
Commonwealth accepts SQL queries over HTTPS and returns results as JSON.
Request Endpoint
All SQL requests, reads, writes, table manipulation, etc., go through the following action.
POST https://api.commonwealth.io/sqlRequest Headers
x-auth-token: The auth token is a 36-character UUID you get from the Commonwealth authentication page. It is optional; if you don't include a token then you can do read queries of public tables.
Request Body
The request body is the SQL query as text (not JSON). You can include multiple SQL queries separated by semicolons. In the case of more than one query, the results will be from the last SELECT query.
Response
{
"success": bool,
"error": {
"message": "",
"row": ,
"col": ,
},
"column_names": [name, …],
"column_types": [string type, …],
"data": [[value, …], …],
"time_ms": [server-side latency]
}Response Fields
Responses come back as JSON which can be evaluated directly in Javascript or handled using a JSON parser. Each of the top-level fields is returned in every request (for example error is returned even if no error occurred).
| success | A JSON bool value that indicates whether or not all of the queries in the body were able to execute. If multiple queries are passed and a false success value is returned it's possible some queries were successful but later ones failed. |
| error | A JSON map showing an error from the first SQL query (of the one or more sent) that failed. |
| column_names | An array of strings that represent the column names returned in the results. You can explicitly change column name results by using 'AS [alias]' in SELECT queries. |
| column_types | An array of strings indicating the data types of returned queries. Possible values are "int64","float64", "bool", "string", "date", "timestamp". |
| data | An array of arrays containing the results of the query. See the table below to understand how different data types are returned. |
| time_ms | How long it took to execute all queries on the server-side. This excludes communication time between the client and the Commonwealth servers. |
Response Data Formatting
Individual columns are returned to look like the following, which lists each column type, an example response, and an explanation.
| int64 | 1230 | Int values are returned as strings because JavaScript Number objects don't have 64-bits of precision. |
| float64 | 123.4567 | Floats are represented with literal values. |
| bool | true | Bools are represented with literal values. true and false are the only possible values. |
| string | "foo" | Strings are UTF-8 values with a max size of 10MiB. |
| bytes | "foo" | Bytes are binary values with a max size of 10MiB. The difference between the string type and byte type is that strings are treated as UTF-8 on the server side which matters in certain cases, such as calculating string length. They are identical when returned through this interface. |
| date | "2010-02-20" | Dates are returned as strings in yyyy-MM-dd format. |
| timestamp | "2010-02-20T13:34:56.123Z" | Timestamps are returned as strings in ISO8601 UTC format, which looks like yyyy-MM-dd'T'hh:mm:ss.SSSSSSSSS'Z'. In this format the sub-second digits are optional, with a total possible 9 digits. |
Example
An HTTPS request to Commonwealth should look like the following. In this case the client is authenticating with the x-auth-token header, which is optional. A SELECT query is passed in the body of the request.
POST /sql
Host: "https://api.commonwealth.io"
x-auth-token: "44444444-4444-4444-4444-444444444444"
select * from users where id = 20384
An HTTPS response looks like the following.
200 OK
Content-Type: "application/json; charset=utf-8"
{
"success": true,
"error": {
"message": "",
"row": 0,
"column": 0,
"code": ""
},
"column_names": [
"id",
"email"
],
"column_types": [
"int64",
"string"
],
"data": [
[
"1",
"foo@bar.com"
],
[
"2",
"syn@ack.com"
]
],
"time_ms": 88
}fetch('https://api.commonwealth.io/sql', {
method: 'POST',
body: `select * from users where id = ${user.id}`
}).then(response => {
if (response.success) {
// Implement your own handling for a successful query
// Example: authUserFromResponse(response);
} else {
throw new Error(response.error.message);
}
});Client Example
You can query Commonwealth from almost any programming language. Here's how you would send a query and handle a response in JavaScript using the Fetch API.
Integrating Commonwealth into Your App
Since you access Commonwealth over HTTPS it's possible to query from almost any language or application. We've kept the SQL API to a single endpoint so that it's easy to integrate.
AWS Lambda
Single-Page App
If your single-page app has a backend then that's the best place to query Commonwealth. You can deploy the access token with your backend code, which would then query Commonwealth over HTTPS.
If your single-page app includes only front-end code you can still use Commonwealth but you should be thoughtful about your permissions. Deploying your Identity Token to the front-end would give anyone full read/write access to all of your tables (that's probably not what you intend). There are two options in this case: you could create a token with permissions safe to deploy, or you could make tables public.
If you create a token specifically for front-end deployment you can specify which tables you'd like to expose, and which actions the front-end client (and by extension, anyone with the token) can execute on the database. Be aware that these are table-level permissions, so that a user that can read their own data may be able to access data from others, depending how you have designed your application.
You can also make tables public to the world - anyone can read these tables by executing SQL on them. For some kinds of data this isn't appropriate, for example a table of your users. For other data it might be a useful way to expose information from your application and even replace a traditional API. For example, a blog might expose a list of its posts in a Commonwealth table, allowing anyone to query the content with SQL.
Backend Service
Using Commonwealth from a service is straightforward: deploy your access token in a secure way such that your app can access it, then send it with HTTPS requests from your application to Commonwealth. Commonwealth's relational data model and SQL dialect is similar to MySQL and PostgreSQL, so you should be able to use it in most of the same places. We don't yet integrate with ORMs like ActiveRecord or SQLAlchemy, but the full range of functionality is accessible through calling the SQL endpoint directly.
Google Cloud Functions
Commonwealth is easy to access from a Google Cloud Function. Use this example as a guideline for integration.
SQL
Commonwealth has a simple SQL dialect based on Cloud Spanner SQL, plus Commonwealth-specific extensions, including transactional syntax (start transaction, commit, rollback). This documentation is meant to help you write Commonwealth SQL.
We've developed aweb SQL Console and the Commonwealth CLI to make SQL easier to work with. They contain custom parsers for this the SQL dialect to give you immediate feedback on your queries and include autocomplete to help you write queries. Since our dialect is based on it, you may also find the Cloud Spanner SQL Documentation useful.
Select Queries
select 1 + 2;select * from example.foo;select col1, col2
from example.foo,
where col1 > 10
and col2 = 20;select foo.id, bar.id
from example.foo
left join example.bar
on foo.bar_id = bar.id;select foo.col1, avg(foo.col2)
from example.foo
group by foo.col1A select query is how you read from a table in SQL. Commonwealth's select syntax is mostly the same as Cloud Spanner.
Select queries usually begin by listing columns that we want to retrieve, e.g. select column_one, column_two, column_three. But they're more flexible than that, you can select arbitrary expressions. This is valid: select 1 + 1, 10 * 15, column_one + 0.85.
If you write * instead of a column name it will select all columns. For example:
select *
from example.fooAn expression can be a table column, a logical operation on table columns, a function call, a subquery, a literal, a case statement, or one of several other patterns.
Each selected expression can be aliased with as [alias], for example, select price * 100 as price_in_cents. The alias determines the name of the expression output in the query result.
Next in a select query comes the from clause, which picks the table we want to query from.
If you want to query multiple tables at once then you'll need to join the table against others. See the Join Documentation for more info.
The following diagrams display the syntax of select queries as parsed by Commonwealth. You can also find more information about select queries in the Spanner Documentation.
select syntax
from_item syntax
join syntax
expression syntax
Join Syntax
select a.id, b.name
from example.foo as a
left join example.bar as b
on a.id = b.id;select a.id, b.name
from example.foo as a
inner join example.bar as b
using id;A join combines two tables together, usually by connecting together on shared data, like a shared id.
[inner] join

An inner join is the default join type and only returns rows that match the tables on both sides of the join.
left [outer] join

A left join returns all of the rows from the table to the left of the join keyword and the matching rows from the table to the right, if found.
right [outer] join

A left join returns all of the rows from the table to the right of the join keyword and the matching rows from the table to the left, if found.
full [outer] join

A full join returns all of the rows from both tables mentioned in the join, even if they don't match the join predicate.
Insert Queries
insert into example.foo (col1, col2)
values
(1, 2),
(2, 3);For example, the following is a valid query.
insert example.users (id, username)
values (0, "testuser");You can also insert multiple rows at once.
insert into example.users (id, username)
values
(0, "testuser"),
(10, "seconduser"),
(15, "thirduser");Since the inserted values are expressions themselves, you can execute more complex inserts.
insert into example.users (id, account_balance)
values
(0, 15 * 30),
(1, 10 + (select max(balance) from othertable));The second form of the INSERT syntax allows you to insert rows pulled from a SELECT query. In its simplest form, you can insert literal values to a single row.
insert into example.users (id, account_balance)
select 123, 500;But the real power of this syntax is the ability to select from one table into another.
insert into example.powerusers (id, account_balance)
select id, account_balance
from example.users where account_balance > 1000;For this to work the types of the the columns from the SELECT query must match those referenced in the INSERT line. The order of columns and column types matter; column names do not. There’s no magic happening here, in that this is a simple select and insert pattern and all the data must be retrieved to the client before it can be inserted. Thus, you probably won’t be able to copy huge tables this way.
The entire INSERT query is evaluated in a single transaction, so multiple subqueries would have the same view of the data, and all inserted rows would appear atomically at once.
INSERT queries should reference each column that is a member of the primary key of the target table or has a type that includes NOT NULL. In other words, if a primary key on non-null column is missing from the column list then the query will fail.
insert syntax
Update Queries
update example.users
set username = "foo"
where id = 150;Update queries manipulate existing rows. These queries will be much more efficient if you include the primary key columns in the where clause, otherwise a table scan may be necessary to locate the target rows. Note that the WHERE clause is required. If you want to update all rows in a table then just use true as the WHERE predicate.
update example.users
set
balance = 0,
username = "foo"
where true;Since the values assigned are expressions themselves, you can do more complex queries such as.
update example.users
set balance = (select max(balance) from users)
where true;
Or even
update users
set balance = balance + 10
where true;The alias is intended to help differentiate between tables.
update example.users as u
set u.balance = (select max(u2.balance) from users as u2)
where true;The values queried in an expression and the update mutations themselves are all applied within the same transaction.
update syntax
Delete Queries
delete from example.users
where id = 5;The query is required to have a where clause. If you want to remove all rows in a table just use true as the expression.
delete from example.users
where true;You can also do more complex queries with the where expression.
delete from example.users
where id = (select max(id) from users);The entire delete query is evaluated in a single transaction, and the ids of the rows that you filter in the where clause must be retrieved to the client. Thus, you probably won’t be able to delete all the rows in a huge table; the transaction will never finish.
delete syntax
Create Table Queries
create table example.mytable (
id string(max) not null,
myint int64 not null,
myfloat float64,
created_at timestamp
) primary key (id asc, myint desc);You can create a new table with the create table command. The table requires at least one column and at least one column in the primary key. Columns default to being nullable, but you can add not null.
Because of the underlying technology we recommend you use a hashed or randomly generated column as the first column in the primary key. This ensures new rows are evenly distributed over the data set, which partitions the write workload over the underlying Spanner splits.
You can create columns of the following types:
| int64 | A 64-bit signed integer with a value from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. |
| float64 | A double (64-bit) floating point variable with IEEE 754 semantics. |
| bool | A boolean value with value true or false. |
| string | A UTF-8 string value with a max size of 10 MiB. When you declare these in a create table statement you must add a size in bytes. For example mycolname string(128). You can also set the size to max as in mycolname string(max). |
| bytes | Bytes are binary values with a max size of 10 MiB. The difference between the string type and byte type is that strings are treated as UTF-8 on server side, which matters in certain cases like calculating string length. As with strings you must add a length when declaring bytes types. |
| date | A date value, canonically represented as YYYY-[M]M-[D]D, with a value between 0001-01-01 and 9999-12-31. |
| timestamp | A timestamp with nanosecond precision, canonically represented as YYYY-[M]M-[D]D[( |T)[H]H:[M]M:[S]S[.DDDDDDDDD]][time zone], with a value between 0001-01-01 00:00:00 and 9999-12-31 23:59:59.999999999 UTC. |
create table syntax
Transactions
-- open transaction
start transaction;
-- debit account 444
update example.accounts
set balance = balance - 20
where id = 444;
--- credit account 777
update example.accounts
set balance = balance + 20
where id = 777;
-- finish transaction
commit;
-- get new account values
-- (these changes aren't visible until committed)
select id, balance
from example.accounts
where id in (444, 777);Commonwealth allows you to execute multiple select and DML queries within a transaction. Open a transaction by running start transaction, manipulate data within the transaction, then execute commit to complete it. None of your changes will be visible until the transaction is committed.
Mutations aren't visible within the transaction either. That's why in the above example we read the new account values after committing, otherwise the select query wouldn't see the changes we made.
Set Select Queries
(select id from example.foo)
union
(select id from example.bar)select *
from example.foo
order by id asc, othercol desc
limit 100 offset 1200(select id from example.foo)
union all
(select id from example.bar)
union distinct
(select id from example.syn)You can concatenate select results by using the union keyword as long as the queries produce columns of the same types. union all, which is the default, includes all rows in the union. union distinct returns only unique rows.
You can order results after the union is performed with an order by clause, this allows you to sort the results in ascending (asc) or descending (desc) order. For example, `order by column1 desc`. You sort by an expression, which means you can sort based on an individual column, or on something more complex, for example order by column1 + column2.
To truncate the results of your query you can apply a limit which only returns a specified number of rows, as in limit 100. This improves performance if you only need a few results, since by default a select query returns all matching results. A limit is applied after the sorting of an order by
But what if you want to limit the size of the returned results AND iterate through the results in batches? A common reason is that you're paginating results. In that case you can use an offset in conjunction with a limit, which moves the starting point of your query by a specified number of rows. For example, limit 100 offset 100 would return the 101st to 200th records of the query results.